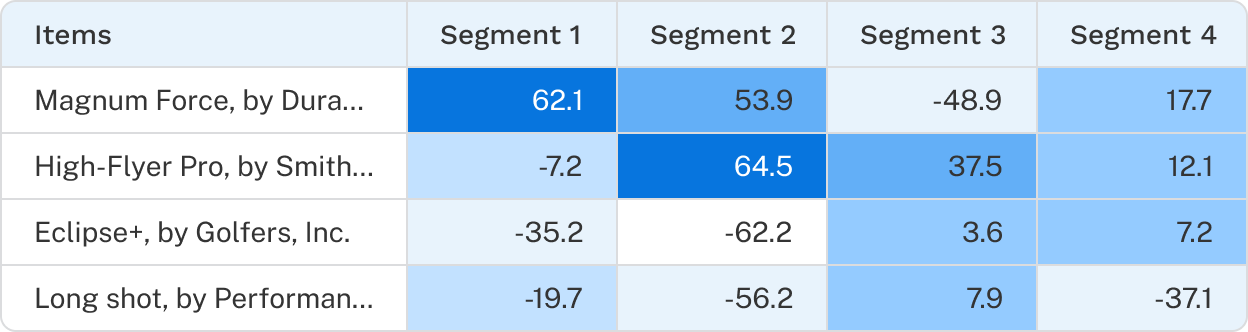
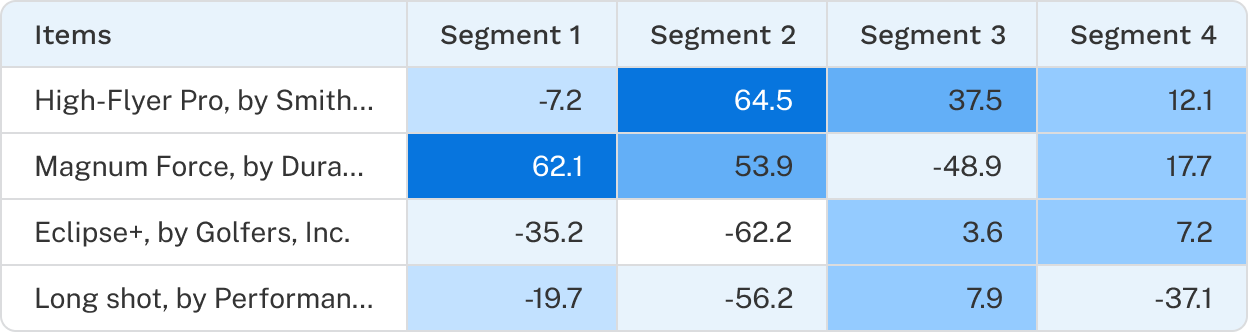
Hierarchical Bayes (HB) utilities segmented by latent class groups and the latent class utilities reported by Segment finder are not the same, though they typically tell a very similar story.
The table below compares Segment finder (latent class) utilities of a 2-group solution compared with the averaged HB utilities for the same groups of respondents.
| |
Latent class segment utilities |
HB utilities segmented |
| |
Segment 1 |
Segment 2 |
Segment 1 |
Segment 2 |
| Brand 1 |
108.3 |
33.7 |
25.4 |
17.0 |
| Brand 2 |
-44.9 |
-1.4 |
-6.7 |
11.9 |
| Brand 3 |
-91.6 |
-43.8 |
-24.9 |
-26.9 |
| Brand 4 |
28.2 |
11.4 |
6.2 |
-2.1 |
| Color 1 |
-11.9 |
-30.2 |
-4.3 |
-22.1 |
| Color 2 |
-25.9 |
-1.9 |
-19.4 |
-14.1 |
| Color 3 |
37.8 |
32.1 |
23.7 |
36.2 |
| Feature 1a |
-8.2 |
0.1 |
-2.1 |
2.5 |
| Feature 1b |
-5.5 |
11.4 |
0.2 |
8.4 |
| Feature 1c |
14.6 |
10.9 |
6.6 |
10.3 |
| Feature 1d |
-0.8 |
-22.5 |
-4.6 |
-21.2 |
| Price 1 |
122.7 |
160.8 |
39.6 |
115.8 |
| Price 2 |
28.4 |
62.3 |
22.0 |
54.2 |
| Price 3 |
-72.4 |
-63.6 |
-19.4 |
-40.3 |
| Price 4 |
-78.7 |
-159.4 |
-42.2 |
-129.7 |
| None |
-584.6 |
228.0 |
-238.5 |
209.0 |
At first glance, the values may appear quite different. However, the correlations between the corresponding segments (Segment 1 : Segment 1 and Segment 2: Segment 2) are both 99%, and the underlying patterns are consistent:
- Brand 1 is generally preferred, with Segment 1 showing a stronger preference than segment 2
- Segment 1 is much less likely to choose the none option
- Segment 2 is more price sensitive, with utility decreasing more as price increases
The differences in this example are expected and stem from several factors, including:
- Differences in model structure (HB MNL vs. latent class MNL)
- The rescaling approach used
- How averaging affects utilities when respondents within a segment disagree
To illustrate this, consider a simple example where two respondents disagree on brand preference but both prefer Blue to Red:
| |
Respondent 1 |
Respondent 2 |
Average |
| Brand 1 |
50 |
-50 |
0 |
| Brand 2 |
-50 |
50 |
0 |
| Red |
-50 |
-50 |
-50 |
| Blue |
50 |
50 |
50 |
After rescaling, each respondent has a total utility range of 200 (100 × 2 attributes).
Now suppose Segment finder groups these two respondents into the same segment. After rescaling that segment to the same total range of 200, the resulting utilities would be:
| |
Segment 1 |
| Brand 1 |
0 |
| Brand 2 |
0 |
| Red |
-100 |
| Blue |
100 |
The overall story is the same — both respondents prefer Blue to Red — but the numbers differ depending on whether rescaling happens at the individual level or from the pooled latent class utilities. Because HB and latent class are also different mathematical models, raw utilities will differ even before rescaling is applied.